How to (semi-) automate Latin Flashcards

I am currently auditing a Medieval Latin course at UNC Greensboro as a test run for potentially finishing my Classics BA next year, however I am struggling with several things: It's been 15 years since I took a Latin course, I was not a good Latin student to begin with the first time, and I work and parent full-time.
I do want to keep up better with class participation, so I need to cram flash cards before class for each reading. What I have come up with to speed up the process, as I am limited on time, is a three (and a half step) pipeline:
- Normalize the Latin text into one word per line: Remove punctuation & numbers, transform to lower case, remove literal duplicates, and place one word per line.
- Use a (somewhat hacky) Python program to run each word through Whitaker's Words to generate definitions, parse the output, and output a tab separated spreadsheet of each definition.
- The resulting spreadsheet is fairly close to complete already by this step. A few rows will need some manual spot checking for errors, and all of the rows with pronouns, prepositions, and common words can simply be deleted.
- There may be some incomplete hits where an entry could be interpreted as several completely different words. I have a copy of the The New Oxford Annotated Bible with Apocrypha NRSV to get a general idea of this week's section first, then at a glance choose the one that makes the most sense.
For example, thecaputinet discriminavit crinem captis suiresulted in three rows:
- capio, capere, cepi, captus V (3rd) TRANS take hold, seize; grasp; take bribe; arrest/capture; put on; occupy; captivate;
- capitum, capiti N (2nd) N fodder for cattle;
- caput, capitis N (3rd) N head; person; life; leader; top; source/mouth (river); capital (punishment); heading; chapter, principal division; [~ super pedibus => head over heels];
Since this is "she combed her hair [on her head]," we can delete the first two.
- There may be some incomplete hits where an entry could be interpreted as several completely different words. I have a copy of the The New Oxford Annotated Bible with Apocrypha NRSV to get a general idea of this week's section first, then at a glance choose the one that makes the most sense.
- Once you are happy with the tab delimited spreadsheet, this should import directly into an Anki app.
Praeambulum
Warning: Technical details ahead.
Colonel Whitaker wrote his Whitaker's Words Latin parser command line app in the 80s using the Ada programming language, which can be a bit fiddly anymore to compile and get working. I used Linux for this; I initially used my MacBook Pro, which curiously had fewer compatibility issues, but I had more Python stuff already set up on my Linux laptop.
In the last few years the Ada community has created a software repository and tool similar to rust's cargo called Alire which has Whitaker's Words as a package that you can pull down and compile in a scripted fashion, and save us the trouble of doing all that work by hand. Unfortunately on Linux (Debian/Ubuntu specifically), there is a bug in the Ada packages that causes Alire not to work at the moment, so I needed to download a specific version of Ada compiler, compile Alire with that myself, then pull down and compile Whitaker's Words.
Normalize the text
Today we have lines 1-8 of book 10 of Judith:
10 Factum est autem, cum cessasset clamare ad Dominum, surrexit de loco in quo jacuerat prostrata ad Dominum.
2 Vocavitque abram suam, et descendens in domum suam, abstulit a se cilicium, et exuit se vestimentis viduitatis suae,
3 et lavit corpus suum, et unxit se myro optimo, et discriminavit crinem capitis sui, et imposuit mitram super caput suum, et induit se vestimentis jucunditatis suae, induitque sandalia pedibus suis, assumpsitque dextraliola, et lilia, et inaures, et annulos, et omnibus ornamentis suis ornavit se.
4 Cui etiam Dominus contulit splendorem: quoniam omnis ista compositio non ex libidine, sed ex virtute pendebat: et ideo Dominus hanc in illam pulchritudinem ampliavit, ut incomparabili decore omnium oculis appareret.
5 Imposuit itaque abrae suae ascoperam vini, et vas olei, et polentam, et palathas, et panes, et caseum, et profecta est.
6 Cumque venissent ad portam civitatis, invenerunt expectantem Oziam et presbyteros civitatis.
7 Qui cum vidissent eam, stupentes mirati sunt nimis pulchritudinem ejus.
8 Nihil tamen interrogantes eam, dimiserunt transire, dicentes: Deus patrum nostrorum det tibi gratiam, et omne consilium tui cordis sua virtute corroboret, ut glorietur super te Jerusalem, et sit nomen tuum in numero sanctorum et justorum.
We need to clean this up into a word list. I manually did the cleanup steps I noted above in the first bullet, using regular expression-based find and replaces in a text editor, then ran that resulting word list file through this awk command I barely understood, but the Internet suggested removes any literal duplicate lines: awk '!x[$0]++'
This gives us our starting list of 138 words:
factum
est
autem
cum
cessasset
clamare
ad
dominum
surrexit
de
loco
in
quo
jacuerat
prostrata
vocavitque
abram
suam
et
descendens
domum
abstulit
a
se
cilicium
exuit
vestimentis
viduitatis
suae
lavit
corpus
suum
unxit
myro
optimo
discriminavit
crinem
capitis
sui
imposuit
mitram
super
caput
induit
jucunditatis
induitque
sandalia
pedibus
suis
assumpsitque
dextraliola
lilia
inaures
annulos
omnibus
ornamentis
ornavit
cui
etiam
dominus
contulit
splendorem
quoniam
omnis
ista
compositio
non
ex
libidine
sed
virtute
pendebat
ideo
hanc
illam
pulchritudinem
ampliavit
ut
incomparabili
decore
omnium
oculis
appareret
imposuit
itaque
abrae
ascoperam
vini
vas
olei
polentam
palathas
panes
caseum
profecta
cumque
venissent
portam
civitatis
invenerunt
expectantem
oziam
presbyteros
qui
vidissent
eam
stupentes
mirati
sunt
nimis
ejus
nihil
tamen
interrogantes
dimiserunt
transire
dicentes
deus
patrum
nostrorum
det
tibi
gratiam
omne
consilium
tui
cordis
sua
corroboret
glorietur
te
jerusalem
sit
nomen
tuum
numero
sanctorum
justorumParsing Whitaker's Words Output
Unfortunately, this is a DOS-era program not meant for this sort of thing, but there are some things we can do to extract the data we need.
I am not interested in the cases and tenses as seen below in the first three lines, and we can turn that off by making a parameters file per the manual.
$ bin/words caput
caput N 3 2 NOM S N
caput N 3 2 VOC S N
caput N 3 2 ACC S N
caput, capitis N (3rd) N [XXXAO]
head; person; life; leader; top; source/mouth (river); capital (punishment);
heading; chapter, principal division; [~ super pedibus => head over heels];DO_DICTIONARY_FORMS and DO_ONLY_MEANINGS set to Y (yes) seems to be what is needed to omit them automatically.
$ cat WORD.MOD
TRIM_OUTPUT N
HAVE_OUTPUT_FILE N
WRITE_OUTPUT_TO_FILE N
DO_UNKNOWNS_ONLY N
WRITE_UNKNOWNS_TO_FILE N
IGNORE_UNKNOWN_NAMES Y
IGNORE_UNKNOWN_CAPS Y
DO_COMPOUNDS N
DO_FIXES N
DO_TRICKS N
DO_DICTIONARY_FORMS Y
SHOW_AGE N
SHOW_FREQUENCY N
DO_EXAMPLES N
DO_ONLY_MEANINGS Y
DO_STEMS_FOR_UNKNOWN NWhich results in the following that is closer to a flashcard format:
$ bin/words caput
caput, capitis N (3rd) N [XXXAO]
head; person; life; leader; top; source/mouth (river); capital (punishment);
heading; chapter, principal division; [~ super pedibus => head over heels];The Whitaker's Words manual states:
"The [XAXBO] is an internal code of the program and is documented below as Dictionary Codes. Several codes are associated with each dictionary entry (presently AGE, AREA, GEO, FREQ, SOURCE). These provide some information to enhance the interpretation of the dictionary entry."
That's neat. Not how I am gonna use it. We can use those square bracketed characters as a marker for a Latin dictionary word line entry.
There are several additional edge cases we also need to account for.
Some words do not display the dictionary entry with the parameters we have set (typically pronouns), just an empty line with the dictionary codes:
$ bin/words vos
[XXXBO]
you (pl.), ye;When we encounter a line with just the dictionary codes we need to insert the searched word back in as the dictionary word.
Another issue I encountered is you cannot assume you will only get one row with a dictionary code per entry, followed by n rows of English. Sometimes you get several dictionary code lines in a row for variants:
$ bin/words lavit
lavo, lavare, lavi, lautus V (1st) [XXXDX] lesser
lavo, lavare, lavi, lavatus V (1st) [XXXDX] lesser
lavo, lavare, lavi, lotus V (1st) [XXXAX]
wash, bathe; soak;I decided to go with the following algorithm:
- Run all of the words through Whitaker's Words and save the output.
- Iterate through each line:
- If a line contained
UNKNOWNin it, skip it - If a line only contained the dictionary code (matched using the regular expression
(\[[A-Z]{5}\].*$)) we need to put the search word back in first as the Latin dictionary entry.- i.e.,
vos [XXXBO]vs.[XXXBO]
- i.e.,
- If a line contains the dictionary entry plus the dictionary code, this is a line that contains a Latin dictionary entry.
- Prepend the line with a
|character as a marker for later. - Remove the dictionary code characters and any notes such as "lesser"
- i.e.,
|lavo, lavare, lavi, lautus V (1st)vs.lavo, lavare, lavi, lautus V (1st) [XXXDX] lesser
- Prepend the line with a
- Otherwise we can assume this to be an English line, and leave it as-is.
- If a line contained
Now you have a set of mostly-cleaned up lines, with the dictionary entries starting with the | character:
...
|sancio, sancire, sanxi, sanctus V (4th) TRANS
confirm, ratify; sanction; fulfill (prophesy); enact (law); ordain; dedicate;
...Note: The following could have also been done in the previous section, but it was easier to debug and iterate on by splitting these parts up.
Now we can loop through this output one more time:
- Skip any empty lines
- If a line begins with the dictionary entry marker we chose, remove the marker character (
|) at the beginning of the line, replace it with a newline character (\n), and end this line with a tab character (\t)- Otherwise continue appending additional lines (stripped of any newlines) until you encounter another line that has the dictionary entry marker character.
At this point you should have a file you can open in a spreadsheet application. I've replaced the literal tab character here with [TAB] to make it easier to see:
...
dominus, domini N (2nd) M[TAB]owner, lord, master; the Lord; title for ecclesiastics/gentlemen;
confero, conferre, contuli, collatus V TRANS[TAB]bring together, carry/convey; collect/gather, compare; unite, add; direct/aim; discuss/debate/confer; oppose; pit/match against another; blame; bestow/assign;
confero, conferre, contuli, conlatus V TRANS[TAB]bring together, carry/convey; collect/gather, compare; unite, add; direct/aim; discuss/debate/confer; oppose; pit/match against another; blame; bestow/assign;
splendor, splendoris N (3rd) M[TAB]brilliance, luster, sheen; magnificence, sumptuousness, grandeur, splendor;
quoniam CONJ[TAB]because, since, seeing that;
...Spreadsheet clean-up
I left the word bank in first-seen order to make it easier to review once the spreadsheet is generated, but you may want to also sort the Latin column alphabetically to find duplicates that were originally just different tenses or cases of the same word for deletion.
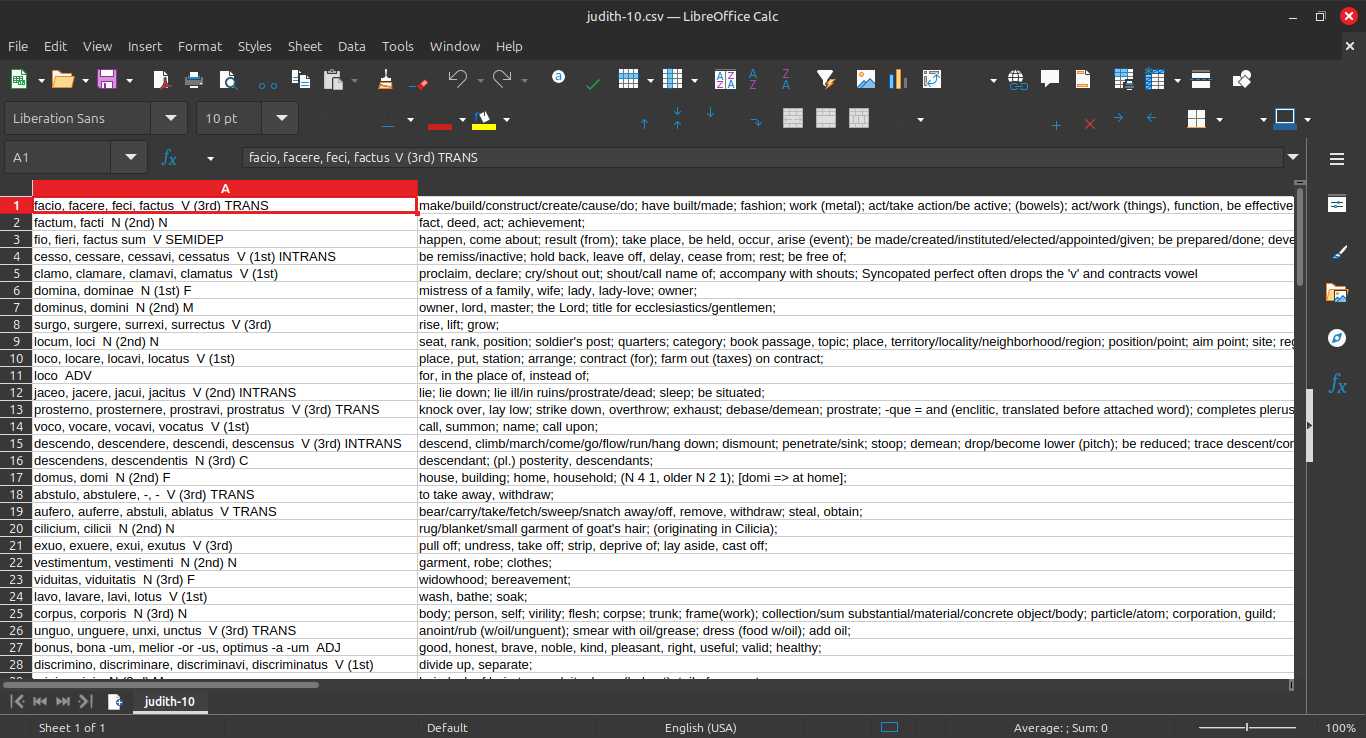
I added a column first explicitly numbering each row before doing any sorting, so I can sort on that column again later and restore the original arrangement.
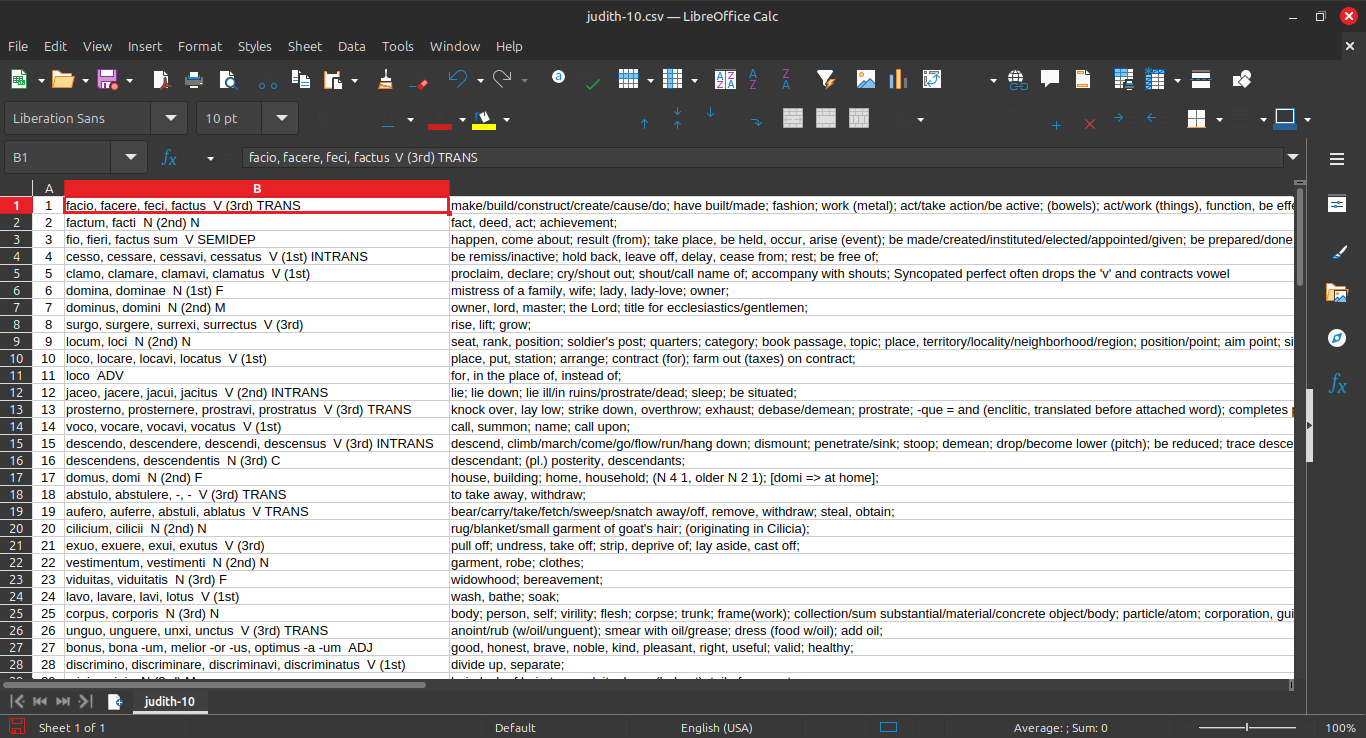
To start with we have 224 rows. Let's delete any common words and obvious duplicates. After deleting the obvious noise we're left with 117 rows. Re-sorting in appearance order we can spot check again for any words that are unlikely to be accurate results for this context. Consulting any provided word bank is also helpful.
Being fairly conservative, I've trimmed down the resulting set to about 100, which is well within a reasonable amount for a week of review.
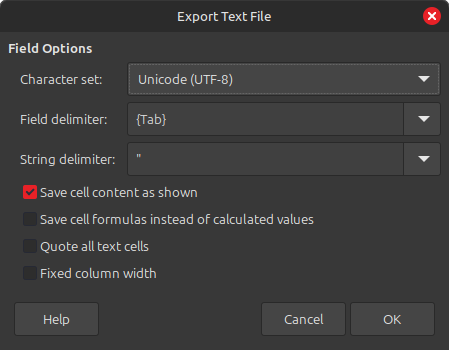
Remove the number column we added, and export the file to a tab delimited CSV.
Anki Import
The defaults should work as-is, but don't forget to make a deck first for this section:
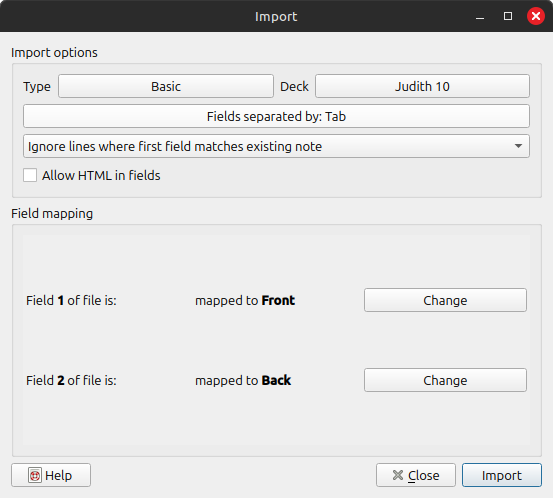
Which results in the following completed flashcards:
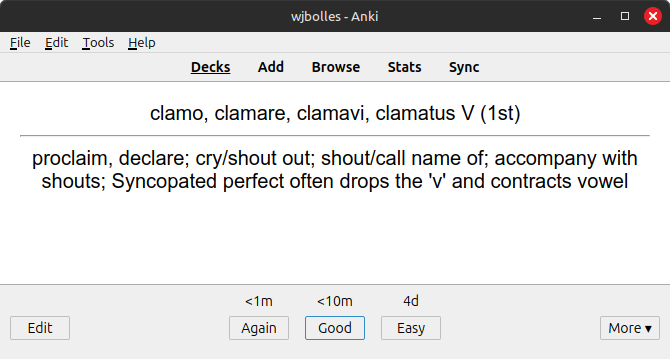
Overall this takes about 30 minutes from start to finish, now that the code has been written. As you review you may see some additional cards that can just be deleted from the Anki deck as you notice them. For example the Factum in Factum est autem resulted in three cards:
facio, facere, feci, factus V (3rd) TRANS make/build/construct/create/cause/do; have built/made; fashion; work (metal); act/take action/be active; (bowels); act/work (things), function, be effective; produce; produce by growth; bring forth (young); create, bring into existence; compose/write; classify; provide; do/perform; commit crime; suppose/imagine;
factum, facti N (2nd) N fact, deed, act; achievement;
fio, fieri, factus sum V SEMIDEP happen, come about; result (from); take place, be held, occur, arise (event); be made/created/instituted/elected/appointed/given; be prepared/done; develop; be made/become; (facio PASS); [fiat => so be it, very well; it is being done]; Before I made the final Anki deck I overlooked the "factus sum" is the one I wanted, not the first two.
Rough draft deck can be downloaded here: https://c.wjboll.es/s/xwsjknpMogw9AE9
Member discussion